AI agents can write code, browse the web, and execute shell commands. What could possibly go wrong?
If you are giving an AI agent a shell, you are basically handing a stranger the keys to your machine. Sure, you can ask the agent to behave — but “please don’t rm -rf /” isn’t exactly a security policy.
I have been exploring sandbox design for AI agents — figuring out how to let them run code, use tools, and interact with the system without blowing everything up. Turns out, Linux already has most of the building blocks. You just have to layer them right.
In this post, we will cover:
- Why sandboxing AI agents is different from sandboxing regular apps
- A defense-in-depth approach using three concentric isolation rings
- The Linux primitives that make it all work — namespaces, seccomp, capabilities, and more
- The subtle gotchas that can bite you if you are not careful
- How different isolation strategies compare
🤖 Why Sandbox AI Agents?
Traditional sandboxing assumes you are dealing with buggy software or a mischievous user. AI agents are a different beast entirely. They don’t just run code — they reason about code. An adversarial agent can analyze its environment, probe for weaknesses, and try creative escape strategies.
Think about the threat categories:
- Privilege escalation — the agent tries to gain root or host-level access
- Data exfiltration — leaking sensitive data over the network, or even through covert channels like DNS queries
- Resource exhaustion — fork bombs, memory bombs, filling up the disk
- Lateral movement — reaching other services on the internal network
- Kernel exploitation — using syscalls to poke at kernel bugs
You might think, “just throw it in a Docker container.” But Docker wasn’t designed with adversarial tenants in mind. Default Docker containers share the host kernel, run with more capabilities than they need, and have a wide-open syscall surface. A determined agent can find gaps.
Full VMs (like Firecracker) give you stronger isolation, but at the cost of heavyweight infrastructure. Sometimes you want something in between — lightweight, kernel-native, and locked down tight.
The key insight: no single security mechanism is enough. You need defense-in-depth — multiple independent layers, each constraining the blast radius, so that even if one layer is bypassed, the others keep holding.
🏰 The 3-Ring Isolation Model
Here’s how I think about structuring a sandbox for AI agents. Picture three concentric rings — each enforced by different Linux kernel mechanisms, each narrowing what the agent can do:
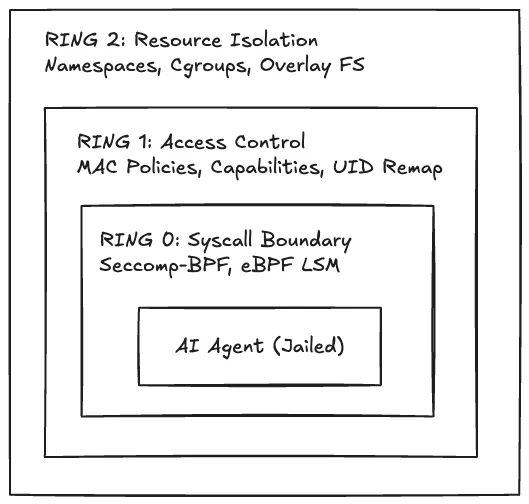
Let’s break each ring down.
Ring 2 — Resource Isolation (Outermost)
This is the broadest layer. It controls what the agent can see and consume.
Linux namespaces are the foundation here. The kernel supports eight namespace types, and a well-designed sandbox uses all of them:
| Namespace | What it isolates |
|---|---|
| PID | Process tree — agent sees itself as PID 1, can’t see host processes |
| Network | Full network stack — agent starts with zero interfaces |
| Mount | Filesystem view — agent gets a throwaway overlay FS |
| User | UID/GID mapping — “root” inside maps to nobody outside |
| UTS | Hostname — agent can’t discover the host identity |
| IPC | Shared memory, semaphores, message queues |
| Cgroup | Cgroup hierarchy — agent can’t see other tenants |
| Time | Clock offsets — prevents timing side-channel attacks |
On top of namespaces, cgroups v2 enforces hard resource limits. You set a PID cap (goodbye fork bombs), memory ceiling (goodbye OOM-killing the host), CPU quota, and I/O bandwidth limits. The agent can thrash all it wants — it’ll only hurt itself.
For the filesystem, an overlay FS gives the agent a read-only view of the base system with a writable scratch layer on top. Everything the agent writes lives in tmpfs and vanishes when the session ends. Ephemeral by default.
Ring 1 — Access Control (Middle)
This ring controls what the agent is allowed to do with the resources it can see.
Mandatory Access Control (MAC) — AppArmor or SELinux — adds path-based or label-based access policies on top of the regular Unix permission model. Even if the agent is “root” inside its namespace, MAC policies can prevent it from reading /etc/shadow or writing to /dev.
Linux capabilities decompose root’s monolithic privilege into ~41 individual capabilities. The sandbox drops all of them. Every single one. Combined with PR_SET_NO_NEW_PRIVS, the agent can never gain new privileges — not through setuid binaries, not through execve, not through anything.
UID remapping is the trick that ties it together. The agent thinks it is running as root (UID 0) inside the sandbox. But on the host? It maps to UID 65534 — nobody. Even if files escape the overlay somehow, they are owned by an unprivileged user on the host.
For unprivileged filesystem sandboxing, Landlock lets you restrict file access without needing root or a MAC policy daemon. It is like a per-process firewall for the filesystem.
Ring 0 — Syscall Boundary (Innermost)
This is the tightest ring. It controls which kernel operations the agent can invoke.
Seccomp-BPF lets you attach a BPF filter to a process that inspects every syscall before the kernel executes it. A whitelist approach: only allow ~60–80 syscalls out of the 300+ available. Everything else returns EPERM or kills the process.
One gotcha that deserves special attention: io_uring. This async I/O interface bypasses the normal syscall path entirely — it submits operations through a shared ring buffer that seccomp can’t inspect. If you are building a sandbox and you don’t explicitly block io_uring_setup and io_uring_enter, you’ve left a wide-open backdoor. Block them unconditionally.
eBPF LSM hooks add another dimension. You can attach eBPF programs to Linux Security Module hook points for runtime policy enforcement and anomaly detection. Think of it as a programmable security layer that can watch for suspicious patterns — unusual file access, unexpected network connections, privilege escalation attempts — and either block or alert in real time.
🔧 The Tricky Parts
The three-ring model sounds clean on paper. In practice, there are subtle gotchas that can undermine your sandbox if you are not careful.
Namespace ordering matters. The User namespace must be created first. Why? Because it enables unprivileged creation of all other namespaces. Without it, you’d need root to set up PID, network, or mount namespaces. Get the ordering wrong and you are either stuck running as root (bad) or failing to create namespaces at all.
pivot_root, not chroot. If you are using chroot for filesystem isolation, stop. A process with CAP_SYS_CHROOT can escape a chroot jail with a simple fchdir to an open file descriptor outside the jail. pivot_root atomically swaps the root filesystem and is much harder to escape. It is what containers actually use under the hood.
Size your tmpfs. The writable upper layer of your overlay FS is backed by tmpfs. If you don’t set a size limit, a malicious agent can write until it fills up your RAM and swap. A simple size=512M mount option prevents this, but it is easy to forget.
Watch for subtle information leaks:
/procand/sysexpose a staggering amount of host information by default — kernel versions, hardware details, scheduling info. You need to mask sensitive paths by bind-mounting/dev/nullover them and usinghidepid=2on procfs.- Time namespace offsets — if you don’t zero out
timens_offsets, the agent can infer host boot time and activity patterns. - DNS as a covert channel — even with network restrictions, if you allow DNS resolution, the agent can encode data in DNS queries (e.g.,
secret-data.evil.com). A whitelist-only DNS resolver blocks this. - 32-bit syscall ABI — on x86_64, the kernel supports both 64-bit and 32-bit (compat) syscalls. If your seccomp filter only checks the 64-bit ABI, the agent can invoke the 32-bit versions to bypass your whitelist. Always verify
AUDIT_ARCH_X86_64in your BPF filter.
⚡ How Do Approaches Compare?
There’s no one-size-fits-all. Different isolation strategies trade off performance, complexity, and strength:
| Approach | Overhead | Isolation Level | Best For |
|---|---|---|---|
| Namespace + seccomp + LSMs | ~1–5% CPU | Kernel-level | High-density workloads, low latency |
| gVisor | ~10–30% CPU | User-space kernel | Strong isolation without VMs |
| Firecracker (microVM) | ~5–10% CPU | Hardware virtualization | Maximum isolation, compliance |
| Kata Containers | ~10–20% CPU | Lightweight VM | Kubernetes-native VM isolation |
The namespace-based approach is the lightest — you are using native kernel primitives with almost no interposition overhead. The tradeoff is that you trust the host kernel’s syscall implementation. A kernel bug in one of your whitelisted syscalls could be exploitable.
gVisor intercepts syscalls in user space, reimplementing large parts of the Linux kernel. Stronger isolation, but you pay for it in latency and compatibility. Not every syscall behaves identically.
Firecracker and Kata give you actual hardware-level isolation via KVM. The agent runs in its own virtual machine with its own kernel. Strongest guarantees, but heaviest footprint.
For most AI agent workloads — where you are running many concurrent sessions and need fast startup — the namespace-based approach hits the sweet spot. But for high-security environments or compliance requirements, consider layering a microVM on top.
🔮 What’s Next: Learning Hypervisors with nova-rs
Working on sandbox design got me thinking about isolation at an even lower level. Namespaces and seccomp operate at the OS level, but what if you could isolate workloads at the hypervisor level?
That curiosity led me to start a learning project — nova-rs, a Rust port of Udo Steinberg’s NOVA microhypervisor. NOVA is a minimal, capability-based microhypervisor (~9,000 LOC C++) that manages hardware virtualization through Intel VT-x. The idea is to port it from C++ to Rust, subsystem by subsystem, as a way to deeply understand both hypervisor internals and Rust’s strengths in bare-metal systems programming.
What makes NOVA interesting from a security perspective: it uses capability-based access control at the hypervisor level — unforgeable tokens that grant fine-grained access to kernel objects like Protection Domains, Execution Contexts, and Portals. These are the same kinds of principles that make OS-level sandboxing work, but enforced one layer deeper.
It is still in the planning stage, and I will share more as I learn. Stay tuned.
🔚 Final Thoughts
Security isn’t one wall — it’s walls within walls within walls. The 3-ring model works because each layer is independent. Bypass seccomp? You still face MAC policies, dropped capabilities, and UID remapping. Escape a namespace? You are still an unprivileged user with no capabilities and a seccomp filter constraining every syscall.
Building this kind of infrastructure in Rust has been genuinely satisfying — the type system and ownership model catches entire classes of bugs that would be silent memory corruption in C. For systems-level security work, that’s not a nice-to-have, it is a fundamental advantage.
If you are interested in sandbox design, AI agent security, or just enjoy reading about Linux kernel internals — stick around. There’s more coming.
— ir2re