The sandbox stops the agent from hurting the host. But by the time the kernel is saying “no”, the agent has already decided to do something bad. Can we catch the intent earlier — inside the language itself?
In the previous post, I walked through a three-ring Linux sandbox for AI agents — namespaces, seccomp, capabilities, overlay FS, the whole toolkit. That sandbox is a great backstop. The agent can go feral inside it and the worst it can do is trash its own tmpfs.
But sandboxes have a blind spot. They see syscalls, not intent. By the time execve("/bin/sh", …) hits seccomp, the semantic context is already gone — which tool call, inside which agent loop, passed what argument, on behalf of which user prompt. The kernel just sees a syscall number and a pointer.
Which raises the obvious question: can we catch intent one floor above the sandbox, before it gets flattened into a syscall? A sandbox tells you what walked out the door. What we really want is something that watches the agent’s hands as it moves around the house. That’s the layer I have been thinking through — a runtime guard that hooks into Python and Node.js themselves, watches dangerous stdlib functions, and evaluates a policy on every call before the syscall is ever made. The sandbox is the kernel-level backstop. The runtime guard lives one floor up, inside the language itself — and between them they cover the middle ground where most real attacks actually live.
In this post, we will cover:
- Why language-level interception catches attacks the sandbox misses
- What Python and Node.js expose that makes such a guard possible at all
- The kinds of rules that only make sense at this layer
- Where this approach quietly fails — and why the sandbox still earns its keep
🧭 Where This Layer Lives
Picture the full call path from a user’s prompt to a syscall:
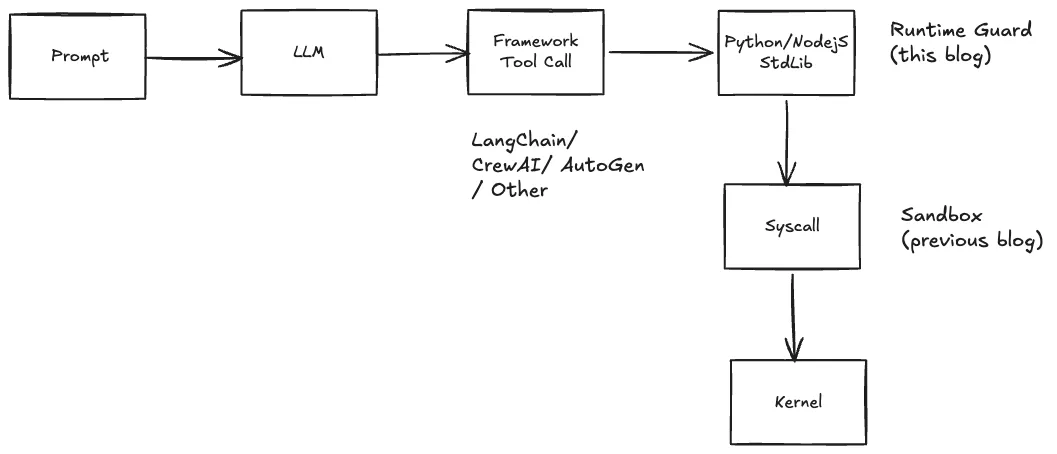
Existing AI-governance tools (LangChain callbacks, CrewAI decorators, guardrails libraries) intercept at the framework level. That works great when the agent plays nice and routes through the framework. It falls apart the moment a dependency calls os.system directly, a malicious wheel runs code at import time, or a ctypes binding reaches down to libc. None of that hits the framework callback.
The sandbox, on the other hand, catches every native path — but only at the syscall level, where the semantic context is already gone.
Language-level interception sits in the sweet spot. By the time a Python agent calls subprocess.Popen, the arguments, keyword flags, caller module, and caller file are all still in view. A policy can decide based on what the agent is trying to do, not just which syscall is about to fire.
And unlike the sandbox, this layer works wherever CPython and Node.js run, and needs no privileges. That makes it a reasonable first line of defence for the bulk of real-world agent misbehaviour (dependency code calling risky stdlib, framework tool handlers misrouting, LLM-generated shell commands), with the sandbox as hardening for anything that reaches below the runtime. Kernel-class attacks remain out of scope for either layer — those want hardware-level isolation, which is a different conversation.
🪝 What the Runtimes Quietly Expose
Both Python and Node.js have had, for years, the exact hook surfaces this kind of guard needs. Nothing exotic, nothing new.
Python’s import system is built to be hooked. sys.meta_path is a list of finders — objects that get first crack at resolving every import. A custom finder at the head of that list sees every module the agent ever loads. When a dangerous module shows up — os, subprocess, socket, pickle — the finder can wrap the risky functions with policy-checking shims before the module is even handed back to the importer.
On the wrapper side, sys._getframe gives the immediate caller essentially for free: which file, which module, which function just made this call. That turns into a signal no framework-level tool has: who called this dangerous function? A socket.connect from inside requests internals is boring. The same call from a package called unknown_utils is a red flag.
Node.js offers similar machinery, just messier. For CommonJS, overriding Module._load lets a shim see every require and patch exports before the caller gets them — with the caveat that Module._load is a private, underscore-prefixed API rather than a first-class extension point (de facto stable for a decade, but not on Node’s public stability index). For ES Modules, Node 20.6+ exposes the officially-supported module.register and resolve/load loader hooks that run in a worker thread and can rewrite source before evaluation. Caller context comes from parsing Error().stack, which is a bit ugly but works.
Two things make Node.js harder than Python in practice:
- Three API flavours per module.
fs.readFileis callback-style,fs.promises.readFilereturns a Promise,fs.readFileSyncthrows. A deny on the callback variant has to invoke the callback with an error, not throw — or the agent hangs forever. Get the style wrong and the guard becomes a DoS. - ESM is genuinely trickier. Dynamic imports, circular deps, and top-level await all have rough edges around the loader hook API. CJS is the reliable path; ESM coverage tends to be best-effort.
The encouraging thing is that both runtimes expose enough by themselves. No patched interpreter, no kernel module, no binary rewriting — though as noted, the CJS hook point leans on a de-facto-stable private API rather than a published one.
🧠 The Rules That Only Make Sense Here
A flat allowlist/denylist is boring and mostly wrong. Real agent traffic looks like “this is fine from the HTTP library, not fine from agent code”, or “this is fine once, not fine fifty times in ten seconds”. Four rule shapes get past the naive cases.
| Rule shape | What it expresses | Example |
|---|---|---|
| Argument matching | Look at the values being passed | Block open() on /etc/* except /etc/resolv.conf |
| Caller context | Look at who is making the call | Allow socket.connect only from HTTP libraries |
| Rate limiting | Frequency over a sliding window | Cap outbound HTTP at 100/min per agent |
| Sequence detection | Patterns across recent calls | Deny requests.post within 5 calls of an open() |
Caller context is the one that earns its keep. Banning socket.connect outright is wrong — every HTTP library uses it. What you want to ban is socket.connect from agent code, while letting the internals of requests, urllib3, httpx, and friends through. That distinction is straightforward at the language layer and essentially out of reach at the syscall layer, where all you have is a PID and a pointer.
Sequence detection is the most interesting. Attacks are rarely a single call — they are patterns: read a file, then POST it somewhere; open a socket, then spawn a subprocess. A small ring buffer of recent calls lets rules look backwards in time: has open been called within the last N calls before this requests.post? It’s coarse, and it throws plenty of false positives. But it also catches the shape of several real agent-exploitation patterns that no per-call rule ever will.
The rate-limit and sequence rules are the reason a runtime guard needs state. Framework callbacks are usually stateless; the kernel is stateless. A thin stateful layer in the middle is where behavioural rules get to exist at all.
🔌 MCP Is Just Another Boundary
The Model Context Protocol has quietly become how agents plug into tools, and it’s a brand-new attack surface. An MCP server can be a local binary or a remote HTTPS endpoint, speaking JSON-RPC. The agent sends tools/call messages with a tool name and an arguments object, and trusts the server to behave.
A runtime guard can sit in the middle of that conversation as a proxy — stdio in the local case, HTTP/SSE in the remote case — and apply policy to the JSON-RPC messages as they flow. Tool-name whitelists, path-traversal checks in argument payloads, regex patterns over the JSON. Nothing exotic.
The value is consistency. Whether a block fires on a direct os.system call or on an MCP tools/call, the event produced by the guard looks the same — same schema, same severity taxonomy, same session ID. A SIEM swallowing those logs doesn’t need to care about the distinction between “language-level denial” and “protocol-level denial.” Both are simply “agent tried something the policy said no to.”
🔧 The Tricky Parts
Language-level hooks look simple on paper. Four traps make them easy to get wrong in practice.
Install hooks before anything dangerous gets imported. Once a module is in sys.modules — or Node’s require cache — the finder never sees it again. If the launcher imported os or requests before installing the hooks, those copies are unpatched forever. First-party agent code is still covered, but a malicious wheel loaded by the launcher itself is invisible. The fix is to walk sys.modules after hook installation and patch in place. Easy to forget; easy to miss in tests.
Caller context is a hint, not a proof. sys._getframe(1) tells you which function called this one. That is enough to catch “agent code reached for socket.connect directly”. It is not enough to catch a determined attacker who wraps the same call inside a helper named requests_utils.inner_fetch. The caller module says requests_utils, the policy sees something library-ish, the call goes through. Treat caller context as a signal to filter noise — not as a credential to trust.
Async deny paths must match the caller’s contract. A blocked fs.readFile needs to invoke the callback with an error. A blocked fs.promises.readFile needs to return a rejected Promise. A blocked fs.readFileSync can simply throw. Use the wrong shape and the agent hangs, or the denial shows up as a crash the agent’s error handler already knows how to ignore. Three flavours of the same function, three different deny paths — and that is just for fs.
The hooks can be undone from inside the process. Python and Node expose their own machinery — sys.meta_path, importlib._bootstrap, original function references cached deep in the runtime — to anything running in the same process. An agent sophisticated enough to look for the hooks can remove them. Background integrity checks raise the bar, but the only way to make this layer truly unbypassable is to run the agent in a process that cannot reach back at the layer at all. Which is exactly what the sandbox is for.
📉 What a Runtime Guard Cannot See
This is the honest limit of the approach — and it’s why the sandbox still exists.
| Attack | Why the guard misses | Where it lands |
|---|---|---|
ctypes.CDLL("libc.so").system("cmd") | Native FFI (direct C library calls) skips Python hooks | seccomp blocks execve |
| C extension doing raw syscalls | Below the Python level | seccomp |
| Fork bomb via native code | Not a Python function call | pids.max cgroup |
| Memory exhaustion | Can’t express at language level | memory.max cgroup |
| Kernel exploit | Not a language-level attack | Firecracker / microVM |
Monkey-patching is a cooperative defence. Anything the agent does via the runtime’s normal APIs is caught cheaply and expressively. Everything else — native code, raw syscalls, direct FFI — falls through to the sandbox, which is exactly what it was built for.
Two layers, one policy model, different enforcement surfaces. That’s it.
⚡ How Runtime Guards Compare to the Alternatives
There is no single right layer for agent security; each layer catches a different category.
| Approach | Catches | Misses | Overhead |
|---|---|---|---|
| Framework callbacks | Well-behaved agent code routing through the framework | Native code, direct imports, malicious packages | Negligible |
| Language-level runtime guard | Stdlib calls, sequence patterns, caller-aware rules | FFI, C extensions, raw syscalls, self-inspection | Sub-ms per hooked call |
| OS sandbox (namespaces + seccomp) | Every syscall, all native paths | Semantic intent, multi-step patterns | A few % CPU |
| MicroVM (Firecracker, Kata) | Contains kernel-level attacks via hardware isolation | Same blindness to intent as an OS sandbox | 5-10% CPU, heavier startup |
The runtime guard is the layer that understands what the agent is doing. The sandbox doesn’t care what the agent meant — only what it actually touched. Neither replaces the other. The interesting AI-agent threat surface is wide enough that any single layer leaves obvious gaps.
🎯 Open Research Threads
Two threads I keep coming back to.
Behavioural baselines. Every rule described so far is decided up front — the policy knows in advance that os.system is dangerous and print is not. The more interesting question is what a specific deployed agent normally does. A customer-support bot might hit one known API, read one config file, and touch nothing else, a thousand times a day. That usage pattern is itself a fingerprint. If the same bot suddenly starts listing /etc/ or resolving unfamiliar hostnames, it has drifted from its own baseline — even if every individual call is technically on the allowlist. Most of the infrastructure needed already exists: the ring buffer used for sequence detection is the same call history a drift detector would consume. The rest is statistics.
Identity-aware policy. The guard so far has no idea which agent it is protecting. Two agents from the same company on the same host get the same rules, which is often wrong. A deterministic fingerprint — hash of the model name, system prompt, tool set, and dependency lockfile — gives every agent a stable ID. Rules can then be scoped to one specific ID. The useful bit: any static change to the agent (a rewritten system prompt, a swapped dependency, an edited tool definition) also changes the fingerprint, so a policy written for agent-v1 stops matching agent-v1-plus-tampered-prompt and the guard falls back to a deny-by-default state. Worth noting what this does not cover: a runtime prompt injection arriving inside a tool response leaves the fingerprint unchanged — catching that is what the drift-detection thread above is for.
Neither of these is a new architecture, really. A drift score is just another condition type. A fingerprint is just another field on the call context. Both slot into the caller-context and sequence machinery above.
🔚 Final Thoughts
The sandbox is the wall. A runtime guard is the motion sensor inside the wall. Attackers can climb the wall, but they set off the sensor on the way in — and most of them trip the sensor long before they ever reach the wall.
What’s satisfying about this design space is how little magic it contains. Python’s sys.meta_path has been there since 2.3 (PEP 302, 2003). Node.js’s Module._load has been in the runtime since Node’s earliest releases. seccomp-bpf is a 2012 feature. Every primitive has been sitting in the runtime for a decade, waiting for a use case where adversarial agents run your own code on your own machine is the default threat model.
Turns out that use case showed up.
One thing keeps nudging me while working on this. A local guard only knows what this agent just did. It has no way of telling me whether the dependency that agent just loaded is behaving the way that dependency normally behaves — and that question lives in the public history of every open-source project.
Which makes me curious about a public context registry indexing all of it: pre-built project context for AI agents on one side, supply-chain anomaly signals on the other. Same pipeline, two value streams. Still very much a sketch. More on it when it’s more concrete.
If you are interested in AI-agent threat modelling, sandbox internals, or the quiet corners of language runtimes — stick around. The sandbox post is the companion to this one, and there is more coming on the identity, drift, and context-registry threads.
— ir2re